Sections
Elements of Machine Learning IV: Sentiment Analysis
[avatar user=”malm” size=”small” align=”left” link=”file” /]
Last week’s post introduced in simplified form the basic operation of word vectors and ngrams. This week I’ll go further and show how those concepts can be combined with labelled data to build a simple sentiment analyser. The approach used here is not one to be recommended for a production NLP (natural language processing) system but rather is presented as an educational aid that helped me to gain a little more understanding. The dataset that will be used for training purposes is the relatively famous Stanford Large Movie Review corpus comprising 25k “highly polar” IMDB film reviews that have been hand labelled as ‘positive’ or ‘negative’. The review zip can be downloaded and unzipped and then processed for loading into a csv that contains two columns ‘review’ and ‘sentiment’ with the latter as the label (or target) which has value 0 for negative and 1 for positive. The csv contents can be read into a pandas dataframe and preprocessed before being split into training and test data ready for classification. Here is a convenience function to do all those steps:
def loadData(csvfile='movie_data.csv'):
print("1. Check if tar.gz has been properly unzipped")
file = 'aclImdb_v1.tar.gz'
base = 'http://ai.stanford.edu/~amaas/data/sentiment/'
url = base + file
maybeDownload(file,84125825)
maybeUnzipTargz(file,[('aclImdb/imdb.vocab',845980)])
print("2. Check if movie reviews have been loaded to csv")
maybeLoadReviewsToCsv(csvfile)
# Print first three rows as a quick check
df = pd.read_csv(csvfile)
print("3. Checking first 3 reviews:\n%s" % df.head(3))
# Clean up the review text
print("4. Apply preprocessor to clean review text")
df['review'] = df['review'].apply(preprocessor)
# Split into training and test data 75:25
ratio = 0.25
print("train:test => %d:%d" % ((1-ratio)*100,ratio*100))
X_train, X_test, y_train, y_test =\
train_test_split(df.review, df.sentiment, test_size=ratio)
print("X_train=%s" % (X_train.shape))
return X_train, X_test, y_train, y_test
At this point we can attempt to use a classifier to see if we can build a model from the training data that provides good accuracy on predicting the right sentiment for the test data. A couple of weeks ago, I highlighted a Python module called tpot that allows for automated classifier selection. It was positioned as a more sophisticated version of the built-in sklearn GridSearchCV functionality. For this IMDB review analysis, I opted to use a Logistic Regression classifier and switched back to using GridSearchCV to provide a steer on the best hyperparameters to use for it and then built a function. That’s rather a complicated way of saying, “here’s one I cooked earlier” along with the code to invoke it:
def bestLogisticRegressionModel(X_train,y_train):
''' Best grid search results '''
tfidf = TfidfVectorizer(strip_accents=None, lowercase=False, preprocessor=None)
lr_tfidf = Pipeline([
('vect', tfidf),
('clf', LogisticRegression(random_state=0))
])
params = {'clf__C':10, 'clf__penalty':'l2',
'vect__stop_words':None,'vect__tokenizer':tokenizer,
'vect__ngram_range':(1,1)}
lr_tfidf.set_params(**params)
lr_tfidf.fit(X_train, y_train)
return lr_tfidf
X_train, X_test, y_train, y_test = loadData()
print("5. Using best found LR classifier hyperparameters")
clf = bestLogisticRegressionModel(X_train,y_train)
print("6. Serializing best classifier to file")
serializeClassifierToFile(clf, 'model.pkl')
testscore = clf.score(X_test,y_test)
print("--------------------")
print("Test accuracy: %.3f" % testscore)
print("--------------------")
This approach yields an accuracy of over 90% in correctly predicting the sentiment of the test review data based on the training review data used to build the model:
1. Check if tar.gz has been properly unzipped Found and verified aclImdb_v1.tar.gz Found and verified aclImdb/imdb.vocab Found and verified aclImdb/imdbEr.txt Found and verified all files from aclImdb_v1.tar.gz 2. Check if movie reviews have been loaded to csv Found movie_data.csv 3. Checking first three movie review entries: ---- review sentiment 0 In 1974, the teenager Martha Moxley (Maggie Gr... 1 1 OK... so... I really like Kris Kristofferson a... 0 2 ***SPOILER*** Do not read this, if you think a... 0 ---- 4. Apply preprocessor to clean up movie review text train:test ratio = 75:25 X_train=(37500,) 5. Using best found LR classification model hyperparameters 6. Serializing best classifier to file. -------------------- Test accuracy: 0.901 --------------------
90% may seem decent but this simple unigram model is easily gamed. For instance, “This movie is great” and “This movie is not great” both come out with positive sentiment. In order to pick up on “not great” being correlated with negative reviews, it is necessary to use bigrams thus:
'vect__ngram_range':(1,2)
However that requires a significant improvement in the memory and performance requirements for the underlying infrastructure. And it still doesn’t deal with the nuances of more sophisticated grammar. For that you need more sophisticated NLP tools and approaches such as spaCy which has the added advantage of co-existing with sklearn. The latter is emerging as a de facto requirement for reaching out to a broad hinterland of amateur and hobbyist machine learning enthusiasts. Arguably, the success of more sophisticated propositions such as Google’s TensorFlow will depend on how accessible they are to that constituency. It will therefore be interesting to monitor the progress of initiatives like scikit-flow, which is attempting to integrate TensorFlow support within the sklearn framework.
The full source for the above worked example is available on Bitbucket here. I hope to return to the IMDB dataset with a combination of scaPy and sklearn assistance in a future post. Even if that route improves upon the vanilla ngram based model, the end result is unlikely to trouble anyone working at the leading edge of NLP development. The video of the world premiere of Viv is well worth watching to get an understanding of what constitutes the state of the art in voice-based natural language processing today. In Viv’s case their remarkable demo is made possible by a patented ‘dynamic program generation’ architecture which is the key enabler for allowing platform expansion which is a whole different approach from the one outlined in this post.
It’s worth considering all this in the light of an excellent commentary piece from Jessica Lessin this week entitled “Machine Learning, AI and Bullshit Detection“. It articulates well the increasing problem non-experts face in understanding, assessing and communicating the relative claimed capabilities of machine learning propositions today:
My own bias, based on years of reporting, is that Google, Facebook and Microsoft are most likely to have advanced versions of these technologies. They have the money to draw top talent and the usage data to advance their technologies rapidly.
But I couldn’t prove that, and most of the sources I talk to don’t really know either. And I couldn’t tell you which of the 7,000 AI startups have functional technologies. And I couldn’t say with confidence that their investors do either.
Artificial Intelligence
- Technological unemployment angst from acclaimed author Yuval Noah Harari whose new book Homo Deus sounds fascinating. In it he will argue that AI “will result in a ‘useless’ class of human“:
“Children alive today will face the consequences. Most of what people learn in school or in college will probably be irrelevant by the time they are 40 or 50. If they want to continue to have a job, and to understand the world, and be relevant to what is happening, people will have to reinvent themselves again and again, and faster and faster.”

- Google is hiring driverless car testers in Arizona. A pretty handsome $20/hour for sitting behind the wheel and doing nothing. 12-24 month contracts too by all accounts. Closest thing there is to basic income right now.
- Quartz preview what a movie script written by an AI would look like. It depicts life:
in a futuristic world, which, according to the computer, is “a future with mass unemployment” where “young people are forced to sell their blood.”

- Google IO took place this week in the US with major announcements covering a range of future technologies including virtual reality (Daydream), virtual assistants (Google Assistant, Allo, Duo) and virtual machines for supporting Machine Learning (Google Cloud Platform) as well as more expected fare such as new Android (N) and Android Wear (2.0) releases. The overall impression was of a company at the top of its game confidently taking aim at all its major platform competitors on numerous fronts. If there was a common theme running through the announcements it was of the central importance of Machine Learning in supporting almost every Google proposition.
- Google Assistant is a voice-driven platform for interacting with search and other Google products broadly analogous to Amazon’s Alexa platform. Just as Amazon’s Echo speaker builds upon Alexa, so Google’s aim with Assistant is for it to provide foundational support for a growing range of use cases:
The assistant is coming in two “expressions,” as Google calls them: a new chat app called Allo and an audio-only, Amazon Echo-like speaker called “Google Home.” Inside each app, Google Assistant has been customized for the platform it’s on. In a chat app, you want a bot that gives simple answers and big, easily tappable links. In a voice-based interface, you want your assistant to be short and to the point — and also do a good job connecting to the other things in your home.
- If Google is right about AI being the future of tech, Apple face existential scale problems that have no easy fix. And there’s little evidence they are doing anything about it:
Becoming a major big-data AI services company doesn’t happen completely in secret and suddenly get released to the world, completed, in a keynote. It’s a massive undertaking, spanning many years, many people, and a lot of noticeable interaction with the world. It’s easier to conceal the development of an entire car than a major presence in AI and services.
- Google’s announcement of a specialised hardware board called a Tensor Processing Unit (TPU) custom-built for running machine learning tasks in the cloud is a great example of what that means in practice. Even Amazon’s AWS does not offer quite this sort of raw compute power today:
[TPU contains] a custom ASIC we built specifically for machine learning — and tailored for TensorFlow. We’ve been running TPUs inside our data centers for more than a year, and have found them to deliver an order of magnitude better-optimized performance per watt for machine learning. … A board with a TPU fits into a hard disk drive slot in our data center racks.
- Google provided this photo of server racks crammed with TPUs used in the AlphaGo matches with Lee Sedol:

- Google IO afforded a spotlight on another area where the company is innovating with hardware namely Project Ara, their attempt at building a modular phone. After encountering a few roadbumps, Ara finally appears to be ready to launch later this year:
The Ara Developer Edition shipping later this year is a 5.3-inch, fairly high-end smartphone. You’ll be able to take it out of the box, turn it on, and use it like a normal Android phone. A big, thick Android phone with a bunch of weird exposed ports, but normal nonetheless.
- Also mentioned in passing at IO, Project Abacus represents an attempt by Google to disrupt not just passwords but also two-factor authentication:
With Project Abacus, users would instead unlock devices or sign into applications based on a cumulative “Trust Score.” This score would be calculated using a variety of factors, including your typing patterns, current location, speed and voice patterns, facial recognition, and other things.
- In relation to Android specifically the standout announcement was arguably the inclusion of a platform feature called Instant Apps. It aims to tackle the app discovery hurdle by obviating the need to download apps at install time. Google also announced a video calling app called Duo separate form Allo. The best Android apps in the world if you take as your guide the 2016 Google Play awards include Houzz for home design:

- Rather less welcome news for Google this week in the shape of the developing EU antitrust case. The Information suggested the ‘smoking gun’ may be the notorious 2012 incident with Acer. It’s hard to see them getting out of this with anything less than a very large fine:
Acer’s 2012 abandonment of an Android smartphone under pressure from Google could be what Europe’s antitrust regulator is citing in its preliminary findings against Google. Some at Google knew the incident could be a potential antitrust problem.
News
- Really interesting insight into how NYT’s clear and consistent stance with the Chinese authorities in which they have refused to go along with censorship has ultimately yielded some success suggesting it may be a viable approach after all:
“the Times has benefitted from a consistent approach to doing business in China. That approach has been relatively simple. They have have refused to compromise on their principles and have delivered the same message to the Chinese authorities – that by not allowing their content to be accessible by all Chinese the authorities are doing themselves a disservice.
What have the authorities done in response? Seemingly, the authorities have loosened their controls. Late last year Times journalists started to receive visas (link is external) to work in China again. Could the New York Times be setting the best path forward for news organizations in China?”
- Al Jazeera asks ‘Do social media giants control the future of news?’
- Whoever owns the news agenda would be well advised to consider the wisdom in this Slack post baldly entitle “Words are Hard“.
Mobile and Devices
- Nokia’s re-entry into mobile phone production through its HMD Global joint venture with Foxconn was widely covered and generally well received. It remains to be seen how they fare in a world tilting away from devices to AI-powered services. Ewen Spence’s recidivist suggestion for their first product seems to miss this point entirely:
Forget your iPhones, put aside the Galaxy handsets, the new dream team can bring back the Nokia 3310. The original sold over 126 million so there’s clearly a demand. A super small handset, rugged construction, that runs Android, could be the ‘typical Nokia handset’ the market is in need of.
- Huawei also have big plans to build a global smartphone brand broadly adopting the model used by Nokia in the 1990’s:
Huawei’s priority this year is a marketing campaign to “address the No. 1 issue that many people don’t know the company — especially in Western countries,” said Glory Cheung, president of marketing for its Consumer Business Group. … Huawei is cultivating a luxurious image for its smartphones that contrasts with Apple’s minimalism. It partnered with luxury brand Swarovski to design a women’s smartwatch.
- Let’s hope they don’t adopt the cultural elements either. Nokia were notorious adherent’s of a complacent “jam tomorrow” strategy which revolved around the next product being the killer one. It ended up in a miasma of mass redundancy for their staff. Jean-Louis Gassée searing indictment of Intel culture suggests the same strategy produced identical results in their case too. Legendary Intel CEO Andy Grove coined the phrase “only the paranoid survive“. Seems that lesson didn’t stick:
‘Just you wait. Yes, today’s x86 are too big, consume too much power, and cost more than our ARM competitors, but tomorrow… Tomorrow, our proven manufacturing technology will nullify ARM’s advantage and bring the full computing power and immense software heritage of the x86 to emerging mobile applications. … Because Intel’s management believed their Just You Wait story too deeply and for too long, 11% of Intel’s workforce — 12,000 people — are in the process of losing their jobs. It’s what Intel gingerly calls a Restructuring Initiative to Accelerate Transformation.’

- Antique telephone switchboards being turned into musical instruments.
- How Arduino is helping to change the game for small scale hardware hackers and ushered in the era of “agile hardware”:
The observation that I was going through a lot of Arduinos also made me realize that my clients had changed. I now work more with artists who are incorporating electronics into their work in ways that weren’t accessible just a few years ago, basement inventors who are taking the plunge to see if their idea will fly, people who need small production runs of 10-100 in a world where “small” often means thousands, and stage magicians who need someone to help them make the next great trick happen.
- Orange Pi vs Raspberry Pi:
Security
- Jihadi cyber capacity and aspiration – the dark web and extremist behaviour online. 33 minutes in they discuss some popular third-party security apps favoured by Jihadi types:
- News from Russia of an app called FindFace that has a better than even chance of recognising a random individual by tallying their photo with their online VKontakte profile:
FindFace can identify random passersby with about 70 per cent accuracy, given two conditions: you need to snap a photo of them, and they need to have a profile on social networking site VK.com. … Russian police officers have used FindFace to solve crimes, for which there were photographs or closed-circuit footage
- The app’s creator suggests you get used to this Orwellian vision of the future:
“A person should understand that in the modern world he is under the spotlight of technology. You just have to live with that.”
- Ray Kroc your time has come in the workplace too with this combined biometric facial and fingerprint attendance system:
“The organization cannot trust the individual; the individual must trust the organization.”

- Ethereum a smart contract blockchain technology which has been highlighted before in the blog is super hot right now and seems important to keep tabs on though TechCrunch suggest skepticism at all the hype:
You should care because decentralized cryptocurrencies like Bitcoin and Ethereum are–or at least could be–essentially an Internet for money, securities, and other contractual transactions. Like the Internet, they are permissionless networks that anyone can join and use. Ethereum optimists might analogize Bitcoin as the FTP of this transactional Internet, with Ethereum as its World Wide Web.
Software Development
- For Jira users everywhere, a mischievous suggestion:
Jira plugin idea "Backlog chaos monkey". Marks 5 random backlog tickets as won't fix. No complaints -> tickets were not actually important
— Alex Salguero (@hasumedic) May 9, 2016
- Pinipa sounds interesting. It’s an Enterprise SaaS product that combines program management tooling with crowd-sourcing. In this blog post, one of their founders explains how the Pinipa team used the tool to help plan and monitor its own development:
Pinipa is for leaders to gain visibility across workstreams, share progress and gather insight with real time analytics and reporting.

Hiring and Startups
- Bravo for the Economist taking a bold stand on the cargo cult of collaboration. As with anything, collaboration is ok in moderation but insufficient attention is paid to its hidden costs. In particular the pernicious impact of constant interruption on one’s ability to think hard about certain types of problem:
The biggest problem with collaboration is that it makes “deep work” difficult, if not impossible. Deep work is the killer app of the knowledge economy: it is only by concentrating intensely that you can master a difficult discipline or solve a demanding problem. Many of the most productive knowledge workers go out of their way to avoid meetings and unplug electronic distractions. Peter Drucker, a management thinker, argued that you can do real work or go to meetings but you cannot do both. Jonathan Franzen, an author, unplugs from the internet when he is writing. Donald Knuth, a computer scientist, refuses to use e-mail on the ground that his job is to be “on the bottom of things” rather than “on top of things”.
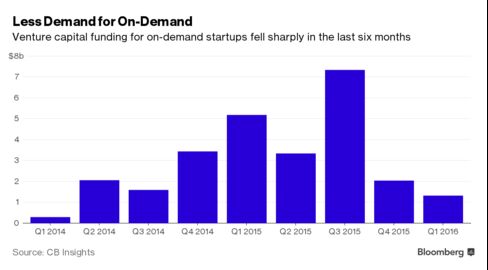
- Bloomberg suggesting that VC interest in ‘on-demand’ services may have peaked already in 2015.
- Hope they’re not using Assistant in Google recruitment already…
Holy smokes. A Google recruiter sent me an email using the skills listed on my LinkedIn Profile.
It is *gold*. pic.twitter.com/1zGkDgRwku
— Paul Fenwick (@pjf) May 11, 2016
- Four words that create a terrible first impression. The wrong response to How are you doing? is apparently “Things are really busy” or variant thereof. Better to say “mustn’t grumble” it seems.
Culture and Society
- Prince and Bowie who both died this year arguably “started streaming music services” building digital subscription models over 15 years ago for a loyal and fanatical fan base:
The late, great David Bowie predicted the future of music back in 2002: “Music itself is going to become like running water, or electricity.” Prince recognized the same thing. In getting their music directly to their fans through digital subscription clubs, both of them looked way beyond CD sales in order to create direct relationships and connections.
- This video on the tech revolution in Senegal is well worth watching to get an insight into the impact technology is having in what is still somewhat patronisingly referred to as the ‘developing’ world by many in the West:
- Whatever the outcome of the US Presidential election, the next incumbent will be faced with a formidable array of issues. This NYT piece looking at the devastating and often unreported consequences of a lethal cocktail of honour culture and gun violence is a harrowing example of a country that seems in danger of lurching backwards not forwards in the next four years.
- A Minimum Wage Machine art installation. Complete with zero hours feature:
The minimum wage machine allows anybody to work for minimum wage. Turning the crank will yield one penny every 4.11 seconds, for $8.75 an hour, or NY state minimum wage (2015). If the participant stops turning the crank, they stop receiving money.
