Sections
Elements of Machine Learning III: Words, Vectors and Code
[avatar user=”malm” size=”small” align=”left” link=”file” /]
Word vectors are a key concept in the application of Machine Learning techniques to textual analysis. A word vector is a multidimensional representation or ‘embedding‘ of a word in a vector space. The simplest possible embedding is called 1-of-N encoding where each word in a vocabulary of size V is uniquely identified by assigning 1 in a single dimension of a vector of length V with all the other V-1 dimensions of the vector set to 0. All V words in the vocabulary can be uniquely assigned this way. It is then possible to use this concept to encode sentences of length C as vectors with corresponding C dimensions combined and normalised to yield a vector of total length 1 with all other dimensions set to 0. In the last few years, Google’s word2vec has emerged as a de facto standard architecture which builds upon 1-of-N encoding with a neural network language model in which the overall ‘context’ (ie. nearest neighbours) of each word in the text are used as input to train the weights of a hidden layer in the neural net. Concretely word2vec builds a internal distributed representation where each word is spread across all inputs which effectively serves as a numerical proxy for the word ‘meaning’. The word2vec architecture is comprised of two models which are mirror images of each other and together constitute an auto-encoder mechanism:
- Continuous Bag of Words (CBOW): allows the prediction of a single word given its context words.
- Skip-gram: allows the prediction of context words given a single input word.
To get a better feel for what this actually means, below is some basic example code that demonstrates how a corpus consisting of four sentences can be represented first as a simple bag of words (BOW) using scikit-learn’s CountVectorizer and secondly as a normalized BOW representation using TfidfVectorizer. The latter stands for “Term Frequency, Inverse Document Frequency” and is a way to score the importance of words (or “terms”) based on how frequently they appear across the corpus. The TfidfVectorizer is initialised to process both single words and bigrams (adjacent words) which allows it to pick out specific uses of the interrogative ‘is the’ albeit at the cost of a bigger vocabulary:
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = ['The sun is shining',
'The weather is sweet',
'Is the sun shining?',
'The sun is shining and the weather is sweet']
def dumpVocab(vocab):
arr = []
for k,v in vocab.items():
arr.append((v,k))
arr.sort()
print(' '.join([(str(v[0]) + ':"' + v[1] + '"') for v in arr]))
print("---- Corpus ----")
print(corpus)
sentences = np.array(corpus)
# 1-gram (individual words)
print("---- 1-gram BOW model ----")
vectorizer = CountVectorizer()
bag = vectorizer.fit_transform(sentences)
print(bag.toarray())
dumpVocab(vectorizer.vocabulary_)
isthe = 'is the'
theis = 'the is'
print("Can we disambiguate '%s' from '%s'? Expect no." % (isthe,theis))
print(vectorizer.transform([isthe]).toarray())
print(vectorizer.transform([theis]).toarray())
# tfidf with ngram_range (1,2) which allows us to
# extract 2-grams of words in addition to
# 1-grams (individual words)
print("---- (1,2) ngram tfidf model ----")
vectorizer = TfidfVectorizer(ngram_range=(1,2))
bag = vectorizer.fit_transform(sentences)
print(bag.toarray())
dumpVocab(vectorizer.vocabulary_)
print("Can we disambiguate '%s' from '%s'? Expect yes." % (isthe,theis))
print(vectorizer.transform([isthe]).toarray())
print(vectorizer.transform([theis]).toarray())
Running the above code yields this output:
---- Corpus ---- ['The sun is shining', 'The weather is sweet', 'Is the sun shining?', 'The sun is shining and the weather is sweet'] ---- 1-gram BOW model ---- [[0 1 1 1 0 1 0] [0 1 0 0 1 1 1] [0 1 1 1 0 1 0] [1 2 1 1 1 2 1]] 0:"and" 1:"is" 2:"shining" 3:"sun" 4:"sweet" 5:"the" 6:"weather" Can we disambiguate 'is the' from 'the is'? Expect no. [[0 1 0 0 0 1 0]] [[0 1 0 0 0 1 0]] ---- (1,2) ngram tfidf model ---- [[ 0. 0. 0.30078176 0.45442879 0. 0. 0.36789927 0. 0.36789927 0.45442879 0. 0. 0.30078176 0.36789927 0. 0. 0. ] [ 0. 0. 0.27304707 0. 0.41252651 0. 0. 0. 0. 0. 0. 0.41252651 0.27304707 0. 0.41252651 0.41252651 0.41252651] [ 0. 0. 0.26887374 0. 0. 0.51524026 0.32887118 0. 0.32887118 0. 0.51524026 0. 0.26887374 0.32887118 0. 0. 0. ] [ 0.30496979 0.30496979 0.31829178 0.24044169 0.24044169 0. 0.19465827 0.30496979 0.19465827 0.24044169 0. 0.24044169 0.31829178 0.19465827 0.24044169 0.24044169 0.24044169]] 0:"and" 1:"and the" 2:"is" 3:"is shining" 4:"is sweet" 5:"is the" 6:"shining" 7:"shining and" 8:"sun" 9:"sun is" 10:"sun shining" 11:"sweet" 12:"the" 13:"the sun" 14:"the weather" 15:"weather" 16:"weather is" Can we disambiguate 'is the' from 'the is'? Expect yes. [[ 0. 0. 0.41988018 0. 0. 0.8046125 0. 0. 0. 0. 0. 0. 0.41988018 0. 0. 0. 0. ]] [[ 0. 0. 0.70710678 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.70710678 0. 0. 0. 0. ]]
It’s important to realise that CBOW and Skip-gram are unsupervised methods which do not require labelled data to work as illustrated above. Having said that, CBOW can be combined with a classifier for example in the case of sentiment analysis where separate individual sentences in the corpus are ascribed a rating of 1 for positive sentiment and 0 for negative sentiment. Training in that scenario results in certain word contexts being more strongly associated with positive or negative. Spam filtering works in a similar way. This combination of unsupervised and supervised learning to derive sentiment is an exercise I hope to return to in a later post.
The inverse process of supplying likely context from word input using a skip-gram model can be employed (albeit after ingesting a lot of training material) to ‘generate’ realistic output like the AI poetry that Wired refer to here:
i went to the store to buy some groceries.
i store to buy some groceries.
i were to buy any groceries.
horses are to buy any groceries.
horses are to buy any animal.
horses the favorite any animal.
horses the favorite favorite animal.
horses are my favorite animal.
For now, it’s worth taking a step back and reflecting on the bigger picture implications of this exercise. Namely that it is possible using Machine Learning concepts like word2vec to derive insight and predictive capability from a corpus purely by training a model on its raw text content alone. You coach not code. This is the profound insight at the core of Wired’s dramatically titled “End of Code” June edition:
In traditional programming, an engineer writes explicit, step-by-step instructions for the computer to follow. With machine learning, programmers don’t encode computers with instructions. They train them. If you want to teach a neural network to recognize a cat, for instance, you don’t tell it to look for whiskers, ears, fur, and eyes. You simply show it thousands and thousands of photos of cats, and eventually it works things out. If it keeps misclassifying foxes as cats, you don’t rewrite the code. You just keep coaching it.

The first public outing of Viv’s much-anticipated AI this week takes things a stage further still. Viv’s creators are Dag Kittlaus and Adam Cheyer who “created the artificial intelligence behind Siri“. They claim Viv is a conceptual leap ahead of Siri in its ability to generate unique code on the fly to handle specific requests:
Onstage it showed off what it claims is a breakthrough: “dynamic program generation.” With every verbal request Viv dynamically spit out code showing off how it understood and handled the request. That would hypothetically allow developers to build out a robust conversational UI for their services simply by speaking to Viv and tweaking the code she generates in return.
The combinatorial advances with the data structures and algorithms and compute power that can be applied to them are happening at an accelerating pace which will profoundly change society in the coming years. It’s hard to be sure that anyone is fully in control or sure of where we’ll end up. Disquiet around that realisation likely underlies Salon’s concern that we need to “fear our robot overlords” and “take artificial intelligence seriously”:
While it’s conceptually possible that an AGI really does have malevolent goals — for example, someone could intentionally design an AGI to be malicious — the more likely scenario is one in which the AGI kills us because doing so happens to be useful. By analogy, when a developer wants to build a house, does he or she consider the plants, insects, and other critters that happen to live on the plot of land? No. Their death is merely incidental to a goal that has nothing to do with them.

Chatbots and HAAI
- According to Facebook’ Messenger’s head of product Stan Chudnovsky, “10k+ developers are building chatbots for M“. It raises some really difficult questions over privacy of user data topic The Information covered well in this article:
How will they explain how they came up with product recommendations, including whether they’re based on data collected about consumer habits or are the result of arrangements with companies? Without an explanation, consumers might not trust the recommendations and therefore be less willing to use the services.
- The question seems all the more relevant in light of evidence that many of us seem to be comfortable conversing with bots, sometimes more so than with humans. We may end up sharing our most intimate thoughts with them to be stored and mined for eternity. There is a certain horrible inevitability about the direction of travel given the underlying commercial imperative is a ‘race to data’:
“Artificial Intelligence algorithms are continuing to improve, however although the algorithms may be open source, the benefits seem to accrue to those with the most data on which to train those algorithms. So the core competency needs not only to be applying the right algorithms to the right problems, but being the primary source for a unique data set.” — Matt Hartman, Director of Seed Investments at Betaworks
- There’s also evidence to suggest we are significantly more inclined to use private messaging rather than public posts on Facebook which is a further indicator:
“Business Insider and Socialbakers just published data at the Engage conference in Prague on communications between customers and companies in Messenger which shows that there are five times as many private messages occurring as there are public wall posts being made on Facebook. Yet company employees on average take 10 hours to respond to a direct message. That suggests there is a huge opportunity for bots to deal quickly with simple questions from customers, freeing up the humans to address the more complicated problems.”
- Another day, another AI messaging proposition backed by millions in VC funding. They can’t possibly all make it can they? This one is called Lola, it’s iOS only and focussed on a single vertical, namely travel bookings, the same space GoButler are targetting. This VentureBeat article covering Lola is interesting mainly for providing some genuine insight into the organisational structure required to support an AI messaging startup:
“What we’re doing now with Lola is we’re not bringing back the old school travel agent, ” he explained “We’re trying to reinvent the travel agency. I have engineers, twenty people on the product team, fifteen travel agents, and ten overhead people like me and the designers. I have five people on the AI team.”

- Speechmatics have announced Arabic transcription support to accompany their existing English audio transcription support. Both can be accessed through REST APIs. An example showing how to access their APIs using Python is provided on their web site.
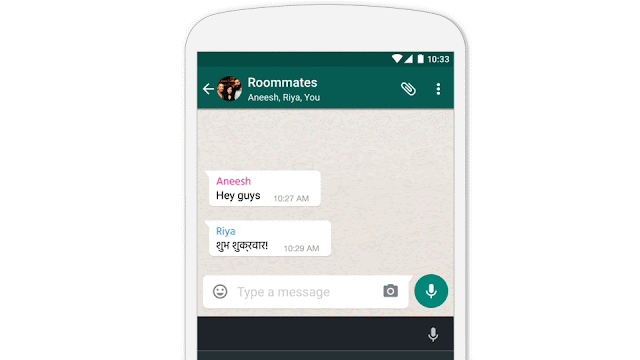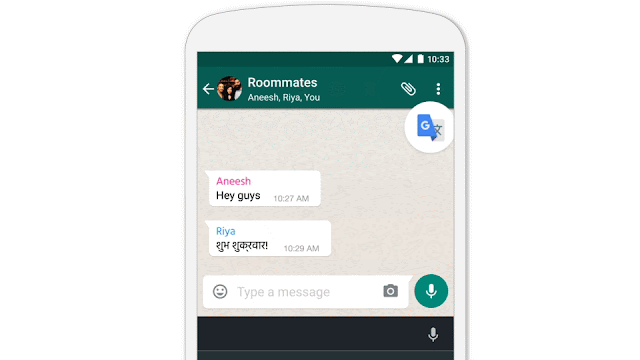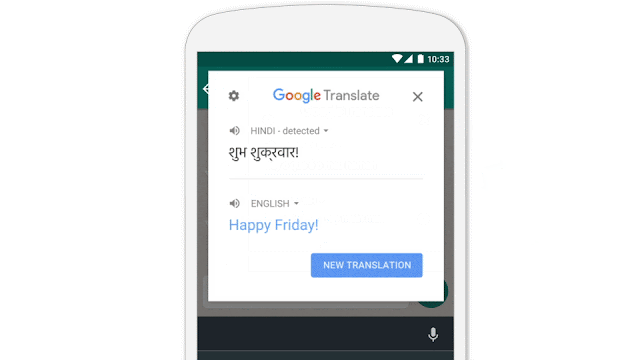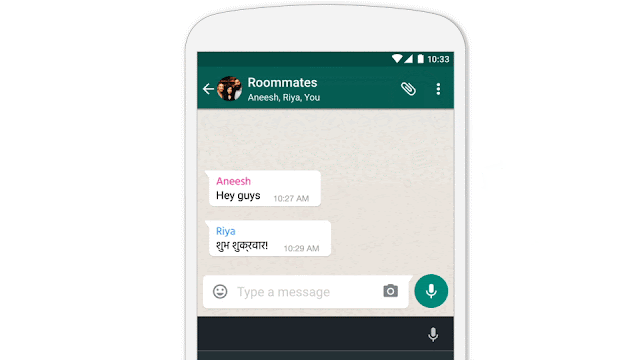
- Google announced some important updates to Translate including live Chinese offline OCR support as well as the ability for developers to access translate functionality wherever they need it within an app in the form of Tap To Translate:
Machine Learning and Artificial Intelligence
- This useful overview of Machine Learning with Python covers essential background material, the scikit-learn stack and classification. The Deep Learning references don’t include TensorFlow though.
- Client-side Deep Learning is becoming a realistic prospect thanks to the latest hardware advances from the likes of Nvidia and Movidius:
Both Nvidia and Movidius see that deep learning is the “next big thing” in computation, which is why Nvidia is optimizing its GPUs for it with each new generation, and why Movidius created a specialized platform dedicated to deep learning and other vision-oriented tasks.
- Relatedly, Forbes seem to suggest further announcements around TensorFlow integration in Android is something we can expect from the forthcoming Google IO.
- Unu, swarm intelligence and correctly predicting the Kentucky Derby:
- AI will “definitely kill jobs but that’s ok” because they’re mostly the boring ones according to import.io Chief Scientist Louis Monier. Maybe they are to him but some of the affected individuals will have a great deal of attachment to their work nonetheless:
In Monier’s AI world, then, the future involves “delegat[ing] to robots/AI the boring jobs, and we keep the good ones for ourselves.” This, he insists, is “just like we have always done, from farm animals pulling the plow to steam power and so on.”
- This video covers similar territory albeit showing how advanced robots are already making irrevocable inroads into Japanese culture and society where in many instances work is already being partitioned between robot and human. It makes for uncomfortable viewing that especially when considered in the light of Monier’s dismissal. Arguably robots are being pushed hardest in the societies where individualism is least valued in some ways:
Google and Apple
- An email Andy Rubin sent a decade ago could yet come back to haunt Google and cost them billions in their ongoing case with Oracle over Android’s use of Java. Uncontroversial and bland is the bar to aim for when it comes to work comms channels:
Be careful what you say in your work email account, or in your company Slack channel, or anywhere a record is kept. You never know when and where it’ll come back to haunt you.
- Apple’s ballooning R&D costs which are on track to exceed a staggering $10billion in 2016 hint up 30% from 2015 at their “biggest pivot yet”.
Digital Transformation (DX)
- McKinsey suggest IT’s new imperative is to focus on partnering and collaboration rather than traditional cost saving concerns. Their analysis suggest organisational structure and operating model and talent issues as remain key blockers to that vision:

- This related McKinsey DX post is also worth checking out. It goes into the specifics of a digital transformation rather than cover the generic high-level non-specific fare you typically encounter on this topic. Interestingly, organisational structure is again at the heart of the machine. McKinsey suggest you need behaviour change instituted top down and a ‘performance infrastructure’ to back it.
- The last word on DX must go to the inimitable Simon Wardley. This talk entitled “Situation Normal, Everything Must Change” from OSCON 2015 is excellent:
Security
- Moxie Marlinspike, founder of Open Whisper Systems and creator of the notorious Signal, was recently interviewed by PopSci robustly defending his position on P2P encryption:
The FBI wants us to believe that strong encryption in consumer products will enable terrorists, but they already have access to encryption. It’s the rest of us that don’t.
- China’s top hackers compete for Geek-Pwn:
- Facebook are turning to schools to help keep their software security hacker employee pipeline going using a version of Capture The Flag.

- They could have just done a real world version of it with Samsung’s SmartThings smart (sic) home platform following the shocking range of security holes found in it by a team of researchers. This is exactly the sort of thing that will continue to deter non-technical customers from embracing ‘consumer’ IoT:
They discovered they could pull off disturbing tricks over the internet, from triggering a smoke detector at will to planting a “backdoor” PIN code in a digital lock that offers silent access to your home
Blockchain and Bitcoin
- Blockchain and Wall Street:
- The BBC go inside a 24-7 “secret Chinese bitcoin mine“:
“All day we mine 50 bitcoins. 24 hours this machine never sleeps.”

The Internet of Things, 3D-Printing and Hardware
- The era of the personal factory is here and is going to profoundly change the game by levelling the playing field for small startups and even individuals relative to established giants. The five key tools at the heart of this revolution are the desktop CNC mill, hi-res and low-res 3D printers, the laser cutter and the router:
The reduced cost of personal manufacturing tools is enabling makers to develop hardware faster than established companies and deliver that hardware directly into the hands of customers even faster.
- This Hybrid Tube Amp for the Raspberry Pi is 4.5 times oversubscribed already on Kickstarter:

- Pocket-sized video game console built with a Raspberry Pi Zero.

- The AWS IoT button:
“For example, you can click the button to unlock or start a car, open your garage door, call a cab, call your spouse or a customer service representative, track the use of common household chores, medications or products, or remotely control your home appliances.”

Science
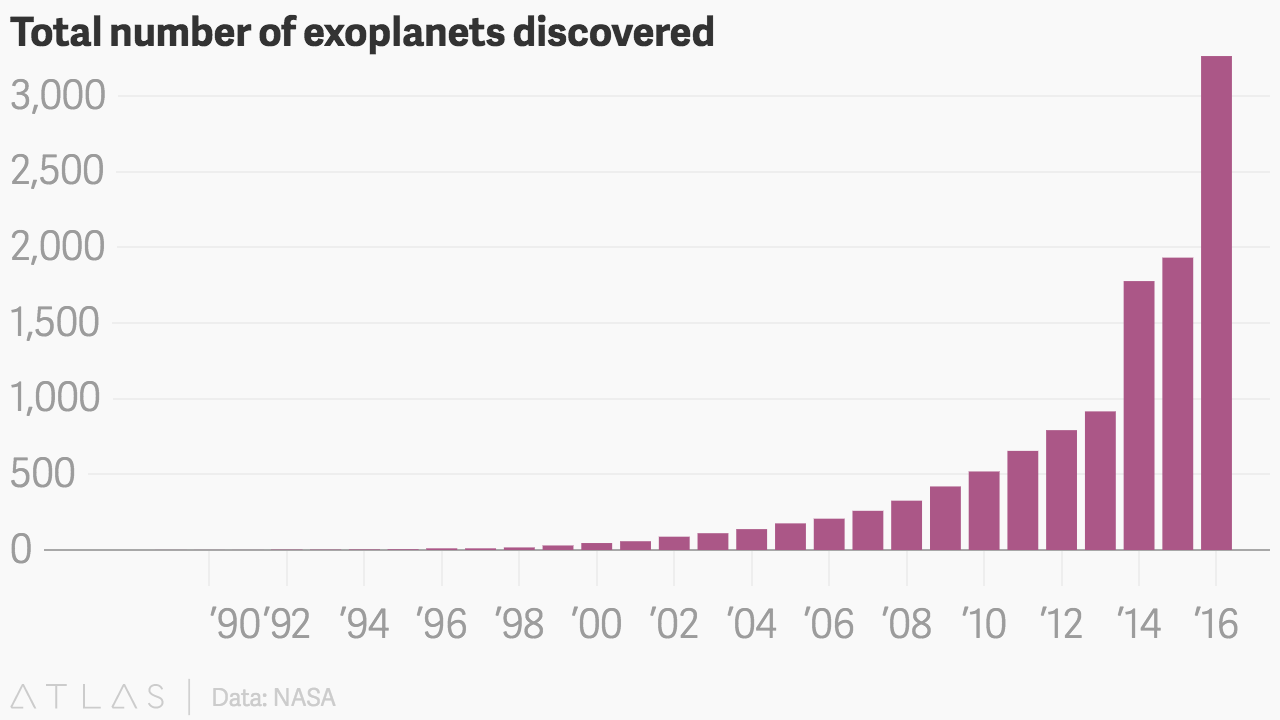
- Regular readers of the blog will know the Fermi Paradox is often namechecked. This Quartz post provides more reasons to worry by highlighting that while the number of exoplanets we have found as a species is increasing exponentially, we face the enormous reality that:
in decades of searching for aliens, we’ve never found any signs. No radio signals. No odd objects arounds stars. No fly-bys of spaceships. Nada. This apparent contradiction is the Fermi Paradox: “Where is everyone?”
Software
- The Python DECO library “automatically parallelizes Python programs, and requires minimal modifications to existing serial programs” using decorators. A good opportunity to wheel out the Python decorator I use for applying parameterised logging to functions:
def logFunction(*args,**kwargs):
log = args[0] # True or False
def fwrapper(fn):
def foriginal(*args,**kwargs):
if log:
print("ENTER: %s(%s)" % (fn.__name__,args))
resp = fn(*args,**kwargs)
if log:
print("EXIT: %s" % (fn.__name__))
return resp
return foriginal
return fwrapper
@logFunction(True)
def doSomething(s):
print("Something: %s" % s)
doSomething('something')
- Alex Vauthey, VP Engineering at LinkedIn on the seven pillars that distinguish merely good from the great software engineers including attention to quality, simplicity and security.
- Despite this, please don’t learn to code if you’re misguided enough to think it’s going to land you a six-figure job:
The truth is, it simply isn’t easy to slide into a development gig, even if it’s an apprenticeship. You need connections, people to vouch for you, a GitHub account maintained over time and more. Despite advances in equal opportunity, if you’re an underrepresented minority, you’re going to have to be twice as good as everyone else. And that’s simply to demonstrate competence.
- Besides, it means you won’t have to face the potential consequences of your mistakes. If you ever had a poor smartphone software update experience, it pales in comparison to the one inflicted on this Japanese satellite:
The cause is still under investigation but early analysis points to bad data in a software package pushed shortly after an instrument probe was extended from the rear of the satellite. JAXA, the Japanese space agency, lost $286 million, three years of planned observations, and a possible additional 10 years of science research.
the Prince symbol is not eligible for inclusion in Unicode, which “does not encode personal characters, nor does it encode logos.” Still, though, the Unicode geeks on mailing lists have talked about it, charmingly using the shorthand TAFKAP (for The Artist Formerly Known As Prince).
![]()
Leadership and Work
- Facebook COO Sheryl Sandberg one year on from a devastating bereavement talks movingly of the experience and how she coped with the help of the framework of the three P’s:
- Personalisation
- Pervasiveness
- Permanence
I hope that you live your life — each precious day of it — with joy and meaning. I hope that you walk without pain — and that you are grateful for each step.
- Scientists on the case for a three-day week. Apparently “over-40s are at their best if they work fewer than 25 hours a week“. That’s my excuse sorted, at least:

- No-one should have strategy in their job title. If you want to make things happen, it’s essential to retain execution resources.
- Richard Branson went out of his way to praise Sadiq Khan’s election as London mayor and contrasted it with the situation in the US:
At a time when the world’s biggest election campaign is being driven by fear, isolation and intolerance, it is great to see Londoners ignore those ugly forces. Congratulations to Sadiq Khan for becoming the first directly elected Muslim mayor of a major western city.
Trump
- There’s only one place to go from there. And the NewYorker’s Adam Gopnik goes there:
Hitler’s enablers in 1933—yes, we should go there, instantly and often, not to blacken our political opponents but as a reminder that evil happens insidiously, and most often with people on the same side telling each other, Well, he’s not so bad, not as bad as they are. We can control him. (Or, on the opposite side, I’d rather have a radical who will make the establishment miserable than a moderate who will make people think it can all be worked out.) Trump is not Hitler. (Though replace “Muslim” with “Jew” in many of Trump’s diktats and you will feel a little less complacent.) But the worst sometimes happens. If people of good will fail to act, and soon, it can happen here.
- Peter Thiel, co-founder of PayPal “a company co-founded by an immigrant (Max Levchin), backed by an immigrant (Mike Moritz) and sold to a company founded by an immigrant (Pierre Omidyar)” may be a notorious Silicon Valley libertarian but he “can’t intellectualize his way out of supporting Donald Trump“:
Donald Trump wants to ban Muslims, and most other immigrants, from entering the United States and talks about women as if they’re his personal sex toys. He wants to cut America off from the world and sees no reason to rule out dropping a nuclear bomb on Europe. Oh, and his own ex-wife has accused him of rape. … These are not the policies of a libertarian, or even of a creationist (which Thiel also claims to be). These are the policies of a fucking asshole. … I can’t speak for anyone else here at Pando, but I’m utterly ashamed that we have him as an investor.
- He forgot to mention abuse of power in relation to Trump’s regular and increasingly threatening broadsides at WashPo owner and Amazon chief Jeff Bezos:
What he’s hinting at is that he would use the anti-trust division of the Justice Department to go after a newspaper publisher who writes stories that he doesn’t like. … In an ordinary democracy, comments like these would practically be disqualifying for a presidential candidate. In America 2016, they barely garner notice. If anything, Trump is using it as a campaign selling point. Perhaps he should create a new tab on his campaign website titled “Planned Abuses of Power.”
Society
- This article about the world of gold cars and binary trading is an eye-opener:


- Wired published a rather disturbing report suggesting that “Phone notifications cause ‘ADHD-like symptoms‘“
- Relatedly, HuffPo explain why sleeping with technology is really bad for you and yet we persist – the stats are alarming and point to serious societal fallout ahead:
The Mayo Clinic says that if you are planning to use a device in bed that you hold it 14 inches away from your face and dim the brightness which further reduces the blue wavelength light from reaching your retina. The National Sleep Foundation goes one giant step further and recommends that you not use any device within an hour of attempting to fall asleep. Given their research showing that 90% of American adults use their electronic devices within an hour of bedtime at least a few nights a week, this may be difficult.
- WashPo again on why age is a liability especially for women:
Age is an even more fraught subject when tangled up with gender. The older gentleman is distinguished. The older woman is . . . haggard. Why do we talk about Hillary Clinton’s age but not Donald Trump’s, although he is a year older?
- Quartz on the dying art of skywriting: