Sections
DIY AlphaGoZero
[avatar user=”malm” size=”small” align=”left” link=”file” /]
The release of a open source version of the AlphaGoZero architecture on Github implemented in pure Python represents another landmark in the progress of arguably Deep Mind’s greatest triumph. Taking up just 1250 lines of code, the source provides an interested observer with a full implementation albeit targeted at Connect 4 rather than Go that can be studied in depth from main.py downwards to understand how the Reinforcement Learning algorithms involved work. The explicit main goals of the project taken from the README.md of the minigo project it builds upon are as follows:
- Provide a clear set of learning examples using Tensorflow, Kubernetes, and Google Cloud Platform for establishing Reinforcement Learning pipelines on various hardware accelerators.
- Reproduce the methods of the original DeepMind AlphaGo papers as faithfully as possible, through an open-source implementation and open-source pipeline tools.
The company behind the codebase, Applied Data Science, previously supplied a handy cheatsheet on how AlphaGo Zero works highlighting the three stages executed in parallel:

Ultimately, however, Brandon Wirtz would have you believe it’s all just linear algebra and you need to stop pretending you’re a genius for knowing how to do it. He suggests all the hype around neural networks and deep learning is essentially built upon the following 11 lines of code which show how to implement a 2-layer neural network complete with back-propagation. Incidentally these same 11 lines of Python were also highlighted in this blog three years ago.

Machine Learning and Artificial Intelligence
A technical take on how to make sense of the bias-variance tradeoff in reinforcement learning which is a bit different from how it works in traditional machine learning where the tradeoff is typically explained in these terms:
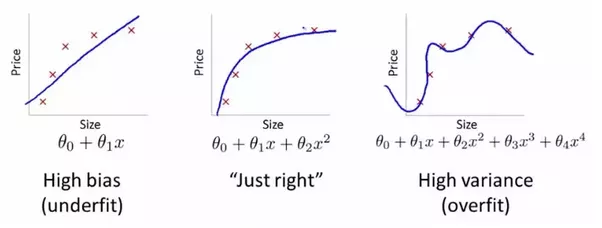
RL is a little different, as it has its own separate bias-variance trade-off which operates in addition to, and at a higher level than the typical ML one. In RL, bias and variance no longer just refer to how well the model fits the training data, as in supervised learning, but also to how well the reinforcement signal reflects the true reward structure of the environment.
RL may lie at the heart of AlphaGoZero and represent one part of the trinity of Deep Learning technologies right now along with RNNs and CNNs. Even so, in keeping with Wirtz’s remarks above, many remain skeptical of their trajectory. The ever-wonderful Douglas Hofstadter in The Atlantic on the “shallowness of Google Translate” points out the manifold flaws of inherent in the perceived miracle of language translation for the masses:
It’s hard for a human, with a lifetime of experience and understanding and of using words in a meaningful way, to realize how devoid of content all the words thrown onto the screen by Google Translate are. It’s almost irresistible for people to presume that a piece of software that deals so fluently with words must surely know what they mean.
By way of example he provides a number of simple but devious linguistic tests including this one for translation into French:
In their house, everything comes in pairs. There’s his car and her car, his towels and her towels, and his library and hers.
which comes out all wrong because “in French (and other Romance languages), the words for “his” and “her” don’t agree in gender with the possessor, but with the item possessed”:
Dans leur maison, tout vient en paires. Il y a sa voiture et sa voiture, ses serviettes et ses serviettes, sa bibliothèque et les siennes.
Wired are also weighed in, building on recent notable callouts from Deep Learning skeptics such as Francois Chollet and Gary Marcus in suggesting that:
deep learning is greedy, brittle, opaque, and shallow. The systems are greedy because they demand huge sets of training data. Brittle because Kwhen a neural net is given a “transfer test”—confronted with scenarios that differ from the examples used in training—it cannot contextualize the situation and frequently breaks. They are opaque because, unlike traditional programs with their formal, debuggable code, the parameters of neural networks can only be interpreted in terms of their weights within a mathematical geography. Consequently, they are black boxes, whose outputs cannot be explained, raising doubts about their reliability and biases. Finally, they are shallow because they are programmed with little innate knowledge and possess no common sense about the world or human psychology.
Chollet is famously the author of machine learning orchestration library Keras where Adrian Rosebrock’s work on building a simple Deep Learning REST API covered in the newsletter last time around has now just been re-published.
Automation doesn’t have to attain consciousness in order to deeply impact society through job replacement. The news that Foxconn’s panel manufacturing arm Innolux are cutting over 10k jobs as robotics take over what were previously human-powered roles is sobering news in that context.
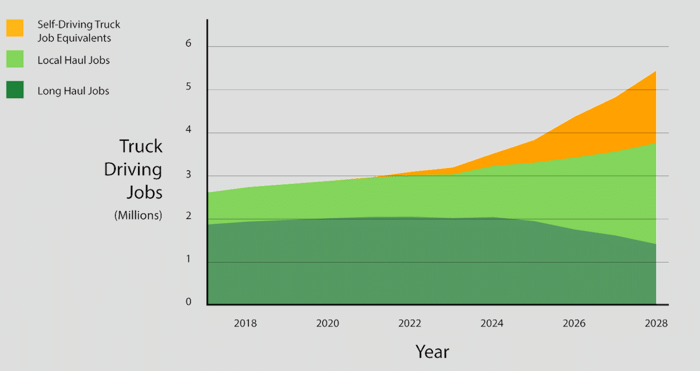
Self-driving vehicles remain the standard bearer for technological unemployment and threaten to eliminate orders of magnitude more human jobs. This article in The Atlantic however provides the counter-argument from an Uber perspective on why it won’t be so bad for truckers:
[Uber] see a future in which self-driving trucks drive highway miles between what they call transfer hubs, where human drivers will take over for the last miles through complex urban and industrial terrain … complementing humans, not replacing them
For Uber, the changing role of truck driving will pan out like this:
Internet of Things and Cloud
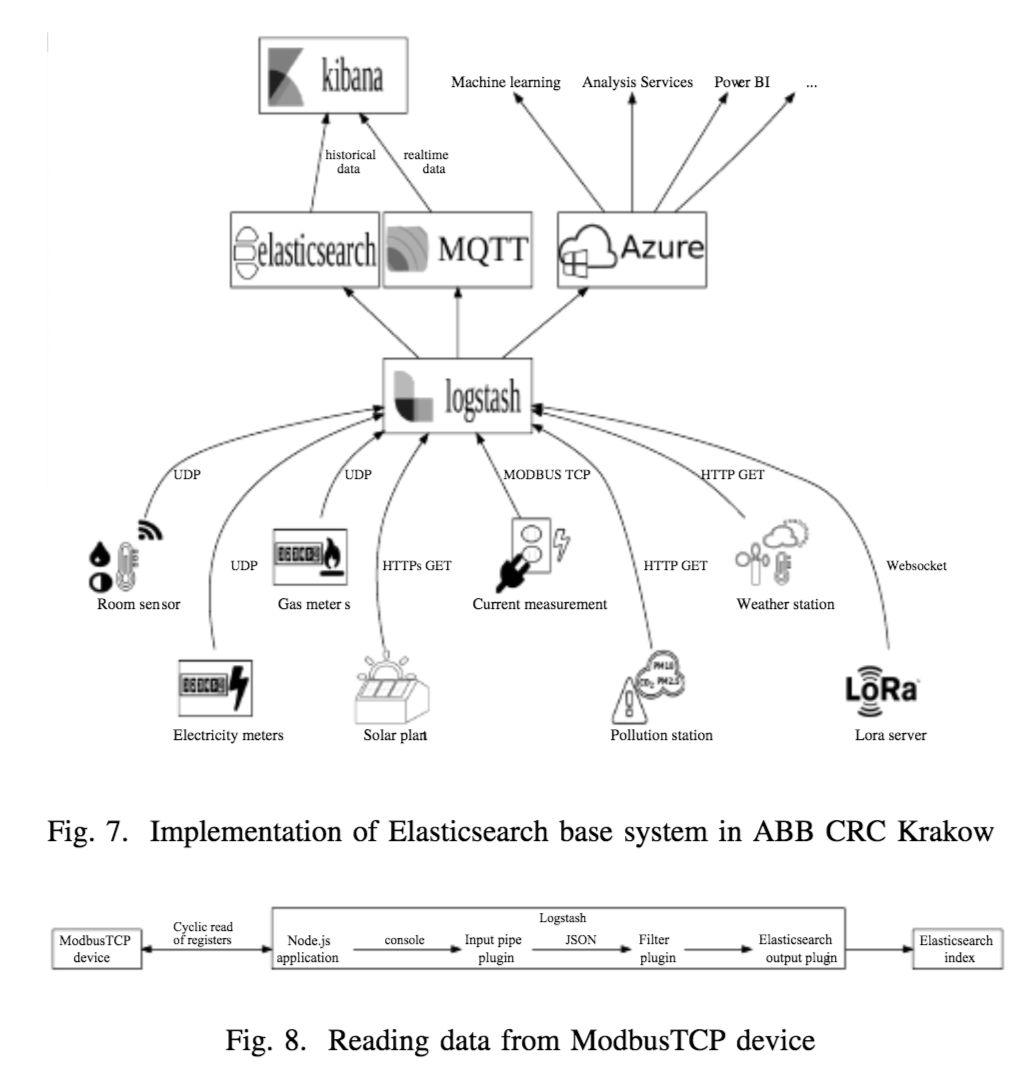
Good primer on how to build an IoT data hub using Elasticsearch with Logstash and Kibana, the famous ELK combo. The architecture diagrams below provide a good indication how different sources of IoT sensor data can be integrated and ‘normalised’ within Logstash before being fed to Elasticsearch for indexing and storage. Kibana can process both real-time and historical data. Note the AWS approved equivalent architecture would involve replacing Azure with AWS and the open source Logstash with AWS Kinesis to yield what AWS term the EKK stack. Really ELK/EKK should be KEL/KEK in terms of layers:
Amazon
With a staggering 92% retention rate, WashPo ask why you cannot quit Amazon Prime even if maybe you should. Because it’s not about economics but convenience:
Prime has mastered something much more valuable: the psychology of being a consumer in an era of too many choices.
The effect was very much in evidence the day Amazon Go store opened:
I’m in Seattle and there is currently a line to shop at the grocery store whose entire premise is that you won’t have to wait in line. pic.twitter.com/fWr80A0ZPV
— Ryan Petersen (@typesfast) January 22, 2018
Even so, our WashPo correspondent isn’t so enamoured with Amazon Key:
Silicon Valley
NYT profile the coming EU General Data Protection Regulation (GDPR) and how Silicon Valley is rising to the challenge of stringent new European regulations on data privacy:
Set to take effect on May 25, the regulations restrict what types of personal data the tech companies can collect, store and use across the 28-member European Union. Among their provisions, the rules enshrine the so-called right to be forgotten into European law so people can ask companies to remove certain online data about them. The rules also require anyone under 16 to obtain parental consent before using popular digital services. If companies do not comply, they could face fines totaling 4 percent of their annual revenue.
Stratechery on Apple at 40, a company now entering middle age after its near-death experience aged 19 when it was famously resuscitated by Steve Jobs:
The fact of the matter is that Apple under Cook is as strategically sound a company as there is; it makes sense to settle down. What that means for the long run — stability-driven growth, or stagnation — remains to be seen.
Whatever happens, it will not die the way it seemed destined to a generation ago:

All the prayers in the world couldn’t help Nokia after Stephen Elop took over. This rediscovered Medium blog post provides an English translation of the notorious Operaatio Elop book published in Finnish in October 2014. The translation conveys a sense of the drumbeat of doom that washed over the company through 2011 and 2012 when it felt like witnessing the fall of the Roman Empire from the inside. I remember being the Cassandra at the Meego party in Dublin in November 2010 and being openly ridiculed. Even I back then could not have imagined in my wildest nightmares the extent of the rout that ensued. Nobody knows anything.
Software Engineering
The code.org team have published an excellent introductory series on how computers work. This is well worth checking out:
The Future Past is already here
The Magic Mirror is a recurring meme for days of future past. Michio Kaku referred to it heavily in Visions, his classic analysis of 21st century technology. This latest proposition from an eponymous startup which has raised $13 million is targeted at the mundanity of home workouts:
This “display” is actually a full-length mirror that consists of an LCD display, surround-sound speakers, camera, and microphone for two-way interactions during live classes. The company also promises that every workout can be performed within the confines of a yoga mat, so you shouldn’t require any further equipment.
When Gibson was writing about Cyberpunk mirror shades, possibly even he didn’t imagine police suspect detection sunglasses would be a thing within 20 years:
A camera on the glasses is connected to a device similar to a smartphone when an officer takes a photo of a person of interest it is sent to the device which then relays the image back to the police headquarters database for comparison and a possible match. … Upon finding a match the app displays all the suspect’s salient information to the officer onsite including, name, nationality, gender, ethnicity and current address. … The technology has already proved successful with seven suspects being identified who have been accused of crimes ranging from hit and run vehicle accidents to human trafficking.

Staying in China, reports of incredible footage showing people flying around in driverless drones like this Ehang model:
Culture and Society
This important and excellent article on Aeon highlights the importance of diversity and why hiring for difference rather than the ‘best person’ makes the difference:
The multidimensional or layered character of complex problems also undermines the principle of meritocracy: the idea that the ‘best person’ should be hired. There is no best person. When putting together an oncological research team, a biotech company such as Gilead or Genentech would not construct a multiple-choice test and hire the top scorers, or hire people whose resumes score highest according to some performance criteria. Instead, they would seek diversity. They would build a team of people who bring diverse knowledge bases, tools and analytic skills. That team would more likely than not include mathematicians (though not logicians such as Griffeath). And the mathematicians would likely study dynamical systems and differential equations.