Analyse This
The “import digest” blog is now into its second year. 2014 saw 36 roundup articles published covering weeks 17 to 52. It is possible to conduct some basic analysis of that corpus to help surface some insights into the published material. This Python-based blog analysis script has been developed as a starting point for that analysis. It has been open sourced in case it is of use for anyone curious about web scraping WordPress content. The script employs a few key Python libraries notably BeautifulSoup and nltk to analyse the contents of the 2014 roundups.
Insights
The script generates this stats.csv file containing rows of data for each roundup which can be opened in Excel and processed to generate the graphs presented below.
One key insight is that the roundup blog articles have got progressively bigger over the year both in terms of raw HTML page size and extracted wordcount. As one would expect, these two properties are strongly correlated as can be readily determined using the built-in Excel CORREL function:
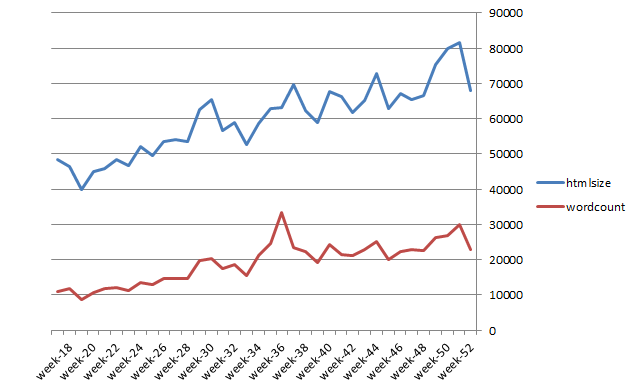
Another insight is that the roundups in absolute terms have become way too big. The overall number of words extracted from all the 2014 roundups was 691,869. That figure is over ten times the average length of a book and 150k words longer than War and Peace! A sensible New Year Resolution would be to start cutting back and regularly monitor progress data to check.
The script is also able to extract frequency counts for words excluding stopwords and punctuation. Aggregating these across all roundup text yields the insight that there is a general bias towards Android and Google related stories over ones involving Apple and there were also around eight mentions a week in the roundups of the term “data”:
- android – 476
- google – 450
- apple – 370
- new – 337
- one – 290
- data – 283
By graphing the frequency of the terms “android”, “google” and “apple” it’s possible to visualise the fluctuations in fortune of these three key themes. Apple was mostly behind the Android/Google figures aside from weeks 37-41 when the Apple Watch announcement and follow-on commentary dominated tech headlines:
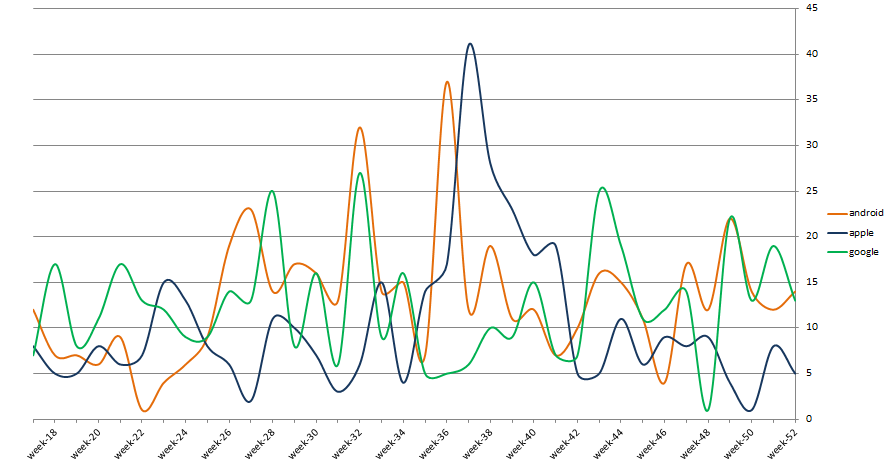
There are plenty of other interesting investigations that could be done on this dataset. A future exercise would be to use Python pandas and ggplot support to generate the graphs instead of Excel.
Implementation details
The blog analysis script implements this recipe:
- Download the collected posts HTML page for a specified year
- Parse this listing to determine all individual roundup locations
- Download all corresponding individual roundup HTML pages
- Process individual roundup pages to extract all published text
- Index across all individual roundup text
- Build a data structure housing information about roundups
- Generate a .csv outputting all collated information
A few implementation details relating to how we home in on blog text are worth elaborating on. Firstly WordPress generated HTML has a certain amount of CSS and JavaScript baggage that can be cut out for text analysis purposes using BeautifulSoup as follows:
soup = BeautifulSoup(html)
for script in soup(["script", "style"]):
script.extract()
Secondly, the content we are interested in appears within a .entry-content div which is created by the TOC+ (Table of Contents) WordPress plugin enabled for each target page. Sections in each roundup are housed under h3 tags. The BeautifulSoup next_sibling method allows us to walk all tags at a peer level to the next h3 thus:
div=soup.select('.entry-content')[0]
for h3 in div('h3'):
section = h3.text.strip()
for sb in h3.next_siblings:
if sb.name == 'h3':
break
try:
text = sb.text.strip()
...
Thirdly nltk can be used to remove stopwords and clean up punctuation issues prior to indexing content for word counts:
stopwords = nltk.corpus.stopwords.words('english')
for block in blog:
t = RegexpTokenizer(r'\w+')
tt = [w.lower() for w in t.tokenize(block)]
words = [w for w in tt if w not in stopwords]
Finally parallelization using Python Multiprocessing support can be employed to speed up the download of HTML files. Using a thread pool of size 4 the script takes ~16 sec to run. In unoptimised serialised mode it take ten times longer, around ~160 seconds.
pool=ThreadPool(4) pool.map(processBlog,bloglist) pool.close() pool.join()