Sections
Self-referential data visualisation VII: First Steps with Machine Learning
[avatar user=”malm” size=”small” align=”left” link=”file” /]
Machine Learning is a topic that has been covered on a number of occasions in this blog. In an effort to better understand its technical underpinnings, I enrolled on Andrew Ng’s famed Stanford University Machine Learning course this week. The first lesson of the course covered Univariate Linear Regression where where a single input variable x used to build a linear hypothesis (or prediction) model h(x) with two parameters or theta values to fit an output y. A cost function J can be defined in terms of the squared errors between the hypothesis function and output y. The idea with linear regression is to minimize this cost function which happens at the point where the sum of the squares of the errors across all m data samples:
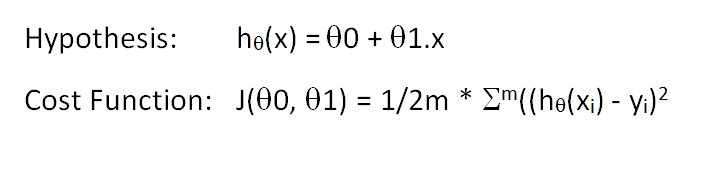 The course material explains how to use Linear Algebra (matrices) to solve for this ‘least square error’. A couple of approaches are outlined. The first involves Gradient Descent which iterates towards an answer. The second is built on the Normal Equation which calculates the minimum. The core tool used for model creation and calculation is Matlab (or OSS equivalent Octave) and the course includes an early crash course in how to use it. It helps to get your head around matrix operations.
The course material explains how to use Linear Algebra (matrices) to solve for this ‘least square error’. A couple of approaches are outlined. The first involves Gradient Descent which iterates towards an answer. The second is built on the Normal Equation which calculates the minimum. The core tool used for model creation and calculation is Matlab (or OSS equivalent Octave) and the course includes an early crash course in how to use it. It helps to get your head around matrix operations.
I wondered if it was possible to apply some of this early learning to the data pipeline framework I’ve been covering over these last weeks. In particular the Dimple plot developed last week shows a clear relationship between HTML size and word count in my blog articles which isn’t altogether surprising really – you’d expect a correlation between those two quantities:
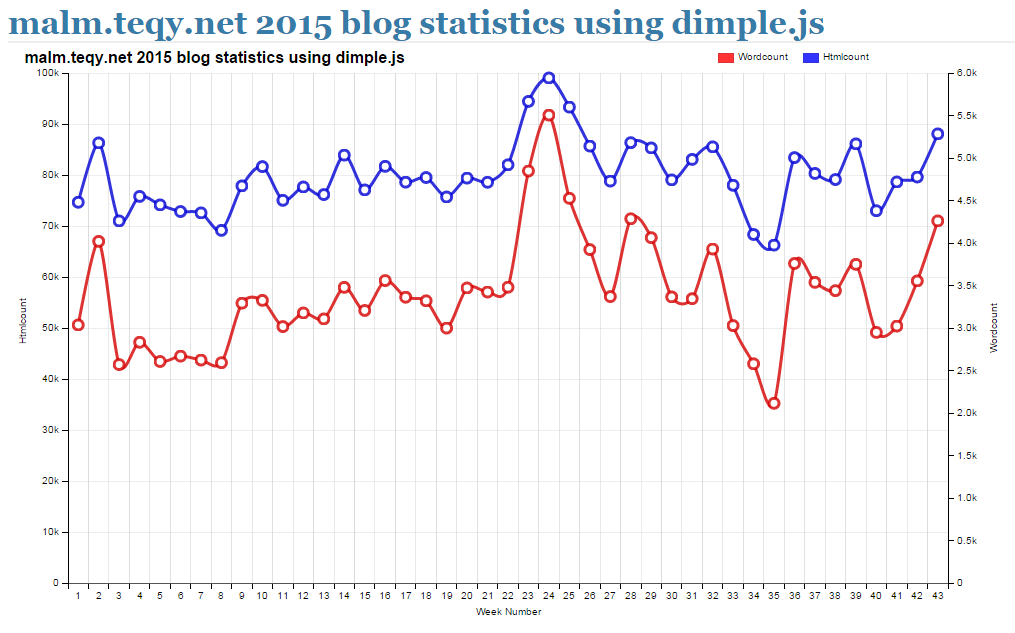
Given this relationship, we can use the initial lesson material to build a linear regression model able to predict word count for a blog post of given HTML size by setting HTML size as our single x variable and word count as y. The Matlab code which does precisely that using both gradient descent and the normal equation is available for inspection here together with the input data it loads. I’ve tried to document the key features for the normal equation case within the source reproduced below. Note that X here represents a matrix and X' is the transpose of that matrix. The % represents a comment in Matlab. Beyond that, I’m not going to try and explain how it works. Suffice to say that within the Matlab IDE, it generates the graph shown further below and the prediction output after it:
%%
% blogAnalysis.m
% -------------
%
%% Initialisation
clear ; close all; clc
%% ==== 1: Load the data ====
fprintf('Plotting WordCount + HTMLsize ...\n')
data = load('blog_summary.txt');
X = data(:, 1); % column 1 = htmlsize
y = data(:, 2); % column 2 = wordcount
m = length(y); % number of training examples
%% ==== 2: Plot the data ====
figure; % open a new figure window
plot(X, y, 'rx', 'MarkerSize', 10); % Plot the data
ylabel('wordcount'); % Set the y-axis label
xlabel('HTML size'); % Set the y-axis label
%% ==== 3: Run Normal Equation ====
% Using closed form solution to linear regression
% to calculate optimal theta values.
% Add intercept term to X
X = [ones(m, 1) X];
% Calculate the parameters from the normal equation
theta = zeros(size(X, 2), 1);
theta = pinv(X' * X) * X' * y;
%% ==== 4: Plot the regression line ====
hold on; % keep previous plot visible
plot(X(:,2), X*theta, '-');
legend('Training data', 'Linear regression');
%% ==== 5: Make and plot prediction ====
htmlsize = 80000;
x = [htmlsize];
% Add intercept term to X
x = [ones(1) x];
wordcount = theta' * x';
fprintf(['Predicted wordcount of a post of HTML size %d ' ... '(using normal equations):\n %0.0f words\n'], htmlsize, wordcount);
plot(x(:,2), wordcount, 'sg');
hold off;
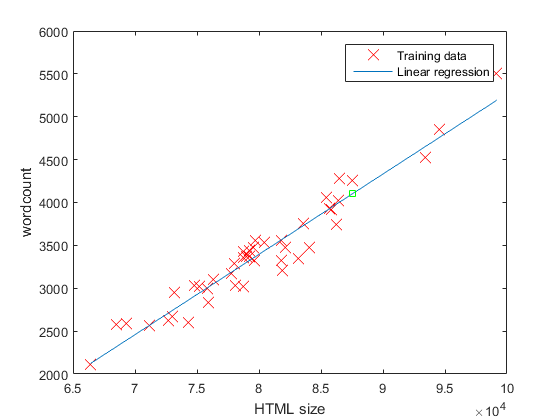
Predicted wordcount of a post of HTML size 80000 (using normal equations): 3396 words
Even if the code doesn’t leap out at you, I hope it conveys a glimpse under the cover at machine learning in action. It’s worth bearing this sort of exercise in mind when you encounter articles trumpeting the latest machine learning advances. As happened this week with Google’s announcement of the open sourcing of its TensorFlow Artificial Intelligence engine. Mind you that really does look like it could prove to be a major development given time as it the tech that powers Google Photos. Even so, it is at the end of the day it is one amongst a number of machine learning libraries like Caffe and Theano. Anyone wanting to leverage any of them would still be well advised to first understand the principles and what’s going on under the hood. Which involves a fair bit of matrix maths.
Mobile and Devices
- The Blackberry Priv received a lot of attention this week as arguably the leader of the pack of the nascent smart cipherphone segment. This TNW reviewer outlines why he considers the Blackberry Priv “one of the best Android handsets I’ve ever used“.
It’s clear that BlackBerry has listened to feedback and considered how best to make a phone that everyone could use, not ridden roughshod over the core OS with its own pointless services and features to create a deformed version of Android that no one should want.

- NYT also previewed the Priv and agree it is a compelling product but one with a high price point at $700 which represents a big bet on the part of the parent company:
“Individuals don’t care about security but they do care about privacy. As much as they care about it, are they willing to pay for it?”
- The Vaporcade Jupiter certainly can’t be accused of being yet another black slab of Android. It’s “a $499 smartphone with a built in vaporizer that will allow you to make calls and smoke fluids with a single magical gadget.” Cue vapourware jokes.
Apps and Services
- NYT parenting blog post on why Snapchat rules the roost for many tweens and offers them a place to be authentic yet safe on the internet:
If apps were cool kids, Snapchat would hold court in the middle of the cafeteria: Its 100 million daily active loyalists are mostly teenagers and millennials. Some 38 percent of American teenagers use it
- Related post explores how teens and tweens are using social media also highlights Snapchat for particular attention:
Young teens’ and tweens’ identities are in flux, so they are especially attracted to the social media photo communication applications like Snapchat. They get the chance to test out personae.

- The Bentley Inspirator is an interesting brand app that integrates facial recognition and “reads customers’ emotions to work out which Bentley Bentayga SUV is best for them“.
https://www.youtube.com/watch?v=sNQglX_6tSA
- Facebook continue to fire on all cylinders as a business in terms of revenue, profits and usage figures:
Facebook had 1.55 billion monthly active users as of Sept. 30, up 14 percent from a year earlier. Of these, 1.39 billion used the service on mobile devices.
- So it seems a little churlish to criticise how they go about development. Nevertheless, at least one commentator feels emboldened enough to have a pop, arguing that Facebook have a real code quality problem. They certainly seem to have a staggering amount of code in their iOS app, which clearly reflects the consequences of their cultural approach to software development, the ‘hacker way’, namely that it encourages a certain NIH mindset and lack of reuse:
Facebook’s solution to a downward curve seems to be to just throw more developers at it until it bends north. I’d never want anyone in my tiny team thinking this is what the cool kids are doing. I’d never want to work this way, but it works for them.
- The article links to an interesting Reddit discussion in which this comment identifies that adoption of this philosophy typically results in perceived ‘visible’ short term gain at the cost of the accumulation of long term technical debt
Hacker culture can let a company move fast and put out features fast. But the cost is poor code quality and lack of long term architecture, which at some point will add up. Essentially living on technical debt to scale fast.
Digital, DevOps and Cloud
- IDC is predicting digital transformation or DX as they term it will go mainstream in 2016. They’ve just published a call to arms research paper which highlights ten key IT-enabled business shifts that every business that wants to remain a business by 2020 needs to recognize and respond to. Among other guidance:
- “Fueling” digital innovation with high-value external data pipelines, and delivering data pipelines into the marketplace to maximize data’s value
- Extending the edge of digital innovation out to the most relevant endpoints in the Internet of Things, building new solutions and services that connect to and deliver value through IoT
- Bringing real-time, “competitive advantage” insights to all employees, partners, and customers by weaving cognitive services into all data-intensive services and apps
- DevOps World took place in London last week. It was a pretty packed and slightly chaotic affair but the presentations were excellent and full of insights from the front line. Two major themes of the event were the “cultural shift to containerisation” and the organisational issues that afflict a Devops transformation particularly in large Enterprise organisations.
- Technical deep dive on Docker networking changes coming in version 1.9 in which the CNM (Container Network Model) debuts.

- How Netflix thinks of DevOps. The thing is that they don’t see it as a process or function – it’s a way of working ingrained in the culture that “if you build it, you run it”. And test it to breaking point and beyond:
- AWS have announced plans to launch a UK specific region by the end of 2016 to complement its existing EU data centres in Ireland and Germany:
The new region, coupled with the existing AWS regions in Dublin and Frankfurt, will provide customers with quick, low-latency access to websites, mobile applications, games, SaaS applications, big data analysis, Internet of Things (IoT) applications, and more.
- Contrarian piece from the CEO of Apprenda on why monoliths are “often better” than microservices. The basic thesis being that monoliths are easier to manage, comprehend and secure because they can be better understood. With the concession midway down that they need to be below a ‘tipping point’ in terms of size in order to exercise these advantages:
Generally speaking, monolithic applications are easier to debug and test when compared to their microservices counterparts.
Security
- NSA School is “how the intelligence community gets smarter secretly“.
- Edward Snowden’s favourite encrypted messaging app, Signal, is now available on Android:
I use Signal every day. #notesforFBI (Spoiler: they already know) https://t.co/KNy0xppsN0
— Edward Snowden (@Snowden) November 2, 2015
- Meanwhile, another of Snowden’s favoured service providers, encrypted email provider Protonmail, has been in the news for the wrong reasons:
Swiss secure email firm Protonmail paid hackers nearly $6,000 to stop them crippling its sites
- Which is a good segue into a Panorama post-TalkTalk episode exploring “how hackers steal your ID?“. It’s a somewhat sensationalist program with an assortment of colorful (and in some cases reformed) characters but it does serve to illustrate how alarmingly easy it can be to penetrate the mediocre security measures that a typical small enterprise might have in place.
- Silent Circle’s CTO Jon Callas published this article on how to approach security solutions in the modern era extolling the virtues of ‘compartmentalization’. Which is essentially sandboxing by another name as employed by virtual machines and for that matter Docker containers.
- Security research explains why 2015 was the “worst year in history for Mac malware“.
Internet of Things and Wearables
- Good Amazon technical documentation on how AWS IoT works end to end from sensor through device gateway to AWS backend services.

- Bluetooth has always been a core technology enabler for IoT but vendors have typically rolled their own protocols over Bluetooth LE. That might be about to change if the standards body has its way:
The Bluetooth Special Interest Group thinks it will soon have an IoT radio specification standard and a new idea for a universal, device-to-device language borrows standards going back to the early days of the World Wide Web.
- VisionMobile presentation on the huge potential that the Industrial IoT sector represents:
- Target sorting shopping list depending on beacon proximity which seems like a perfect example of a use case that isn’t necessarily that technically complicated but certainly has the flavour of magical future about it:
Target sorting shopping list based on path in store via beacons. Amazing pic.twitter.com/f47KTE1gjQ
— Steve Cheney (@stevecheney) November 8, 2015
- CNN preview leading consumer drone manufacturer, China’s DJI:
- Interestingly DJI just took a minority stake in iconic camera technology brand Hasselblad.
- Hackaday on Compressorhead, “the best robot band ever”:
- Tag Heuer announced a luxury Android Wear smartwatch called the Carrera Connected “that you’ll be able to trade in for a mechanical version after two years if the whole connected lifestyle really isn’t for you.“

- TechCrunch remain to be convinced it will be successful though. Here’s an initial hands-on:
- Xiaomi Mi Band 1s now has an integral heart rate monitor and is priced at a giveaway $16.

Artificial Intelligence
- NYT assess a McKinsey report on workplace automation which suggests that rather than making humans redundant, the introduction of business process automation in the workplace will change the nature of work humans do. Landscape gardening seems to be a good bet if you want to avoid the juggernaut of technological unemployment.
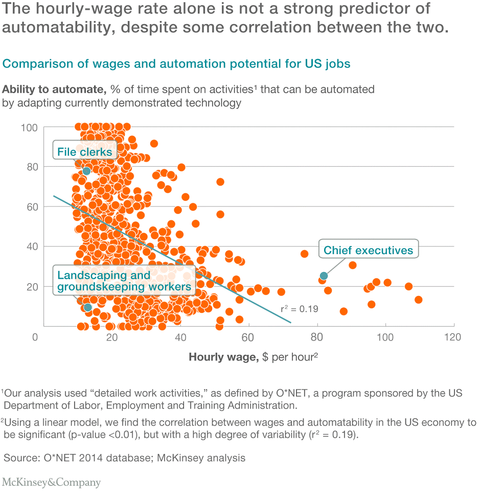
- The Guardian covered the same theme from a UK perspective after digesting a 300-page report on the same topic from BAML which suggested up to a third of UK jobs could be displaced in the next 20 years. Among those in line for disruption are care workers for the elderly:
Care workers Merrill Lynch predicts that the global personal robot market, including so-called “care-bots”, could increase to $17bn over the next five years, “driven by rapidly ageing populations, a looming shortfall of care workers, and the need to enhance performance and assist rehabilitation of the elderly and disabled”.
- Fortune profile John Giannandrea, Google’s AI chief.
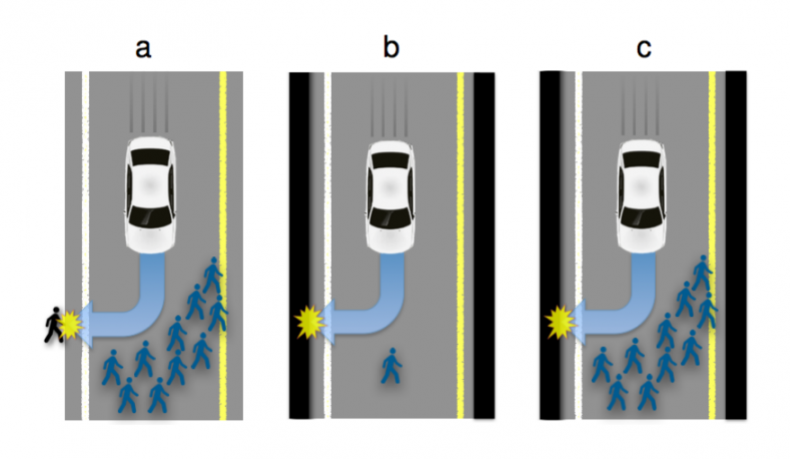
- From a strictly narrow utilitarian perspective, this article explains why self-driving cars must be programmed to kill if it is for the ‘greater good’. This diagram illustrates the basic use case:
Management
- Tim O’Reilly in another good post from his WTF Economy series on why distributed teams represent the “next big economic sea change”. Arguably they also offer an easier glide slope for facilitating robotic integration. Maybe Slackbot is a genuine glimpse of a future foretold rather than an annoying toy?
All of these new technologies, along with the super-hot hiring crisis in some locations, is encouraging more and more companies to try “distributed teams”. This sea-change towards distributed teams has impact rippling out across multiple industries, society in general and our global economy.
- The last in a four-part waitbutwhy series from Tim Urban trying to decode the secret sauce that drives Elon Musk. It makes for somewhat strange reading with Musk coming across as a curious mixture of data-driven geek and martinet. Urban suggests he has a clear model of the world and all his actions are consistent within that model:

- Long and insightful FirstRound post on how AltSchool rebuilt Google’s performance review system to adapt to startup growing pains. One of these involves employee ‘bus factor’ an institutional hazard in small fast-moving organisations:
You want your star performers to not fail the bus test. You don’t want to be fully dependent on them. We’re formal about that, and we put the burden on the individual to come up with a solution if we do think they’re a single point of failure.
Startups and Innovation
- More evidence of the European ‘digital recession’ introduced last week emerges from a fascinating and detailed study published by strategy-business.com on the New World Order in innovation that has emerged over the last eight years in which Asia and the US are dominant and Europe falling further behind. The material in here really ought to set alarm bells ringing right across the EU at a time when it is arguably under existential threat in political terms. Not good:
The most dramatic change in global flows of innovation spending has been Asia’s rise as the number one location for corporate R&D. … The hollowing out of innovation capabilities is happening more noticeably in Western Europe, which has seen the steepest fall in R&D activity.
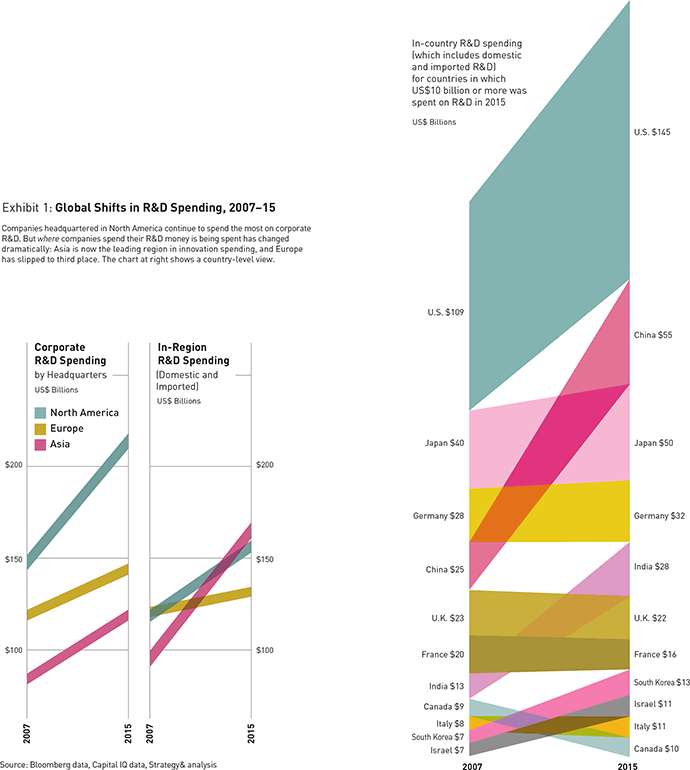
- Another good FirstRound post from an ex-Googler on how to build a brand that matters using the three P’s – purpose, position and personality. A key tool introduced in it is the following value proposition template:

Culture and Society
- NYT on how older workers are finding a way back in after years out of the game in large part thanks to the retraining opportunities offered by online training.
- In another perspective on age and time, this beautiful Nautilus piece on the strange persistence of first language brings to mind the mournful inner worlds of W.G. Sebald’s haunted characters in The Emigrants.
Those of us who received more than one language before the valves of our attention closed may find, to our surprise, that our earliest language lingers on in our soul’s select society, long after we thought it had faded.

- Alibaba founder Jack Ma has a refreshingly zen take on money and the trappings of wealth:
To me, money is a resource that I can use. But the more money you have, the more things you have to do. When they talk about China’s richest man, that is also the man with the most responsibilities. I didn’t know that until I experienced it.
- Nobel prizewinning economist Joseph Stiglitz has similar views on how to make money work for society. In this Atlantic post he explains “how to fix inequality” by massively disrupting rent-seeking or “the practice of increasing wealth by taking it from others rather than generating any actual economic activity” wherever it is encountered:
“Stiglitz suggests a 5 percent increase to the tax rate of the top 1 percent of earners—a move that he says would raise as much as $1.5 trillion over 10 years.”
- However, the author injects this note of caution into proceedings:
“The world that Stiglitz envisions in his book, one where all citizens can enjoy the promise of education, employment, housing, and a secure retirement seems at once like the realization of the American dream and an unattainable utopia.”
- An organisation called VHEMT offers an altogether different and darkly nihilistic solution, an alternative eschatology:
“there is a group of extremist hippies called the Voluntary Human Extinction Movement (VHEMT, pronounced “vehement”) that actively promotes the idea that humans should stop breeding, and allow ourselves to go extinct. As their motto puts it, “Live long and die out.”
